別用平均值(Average)或中間值(Median)來評價服務器反應效能,應該用百分位數(Percentile)
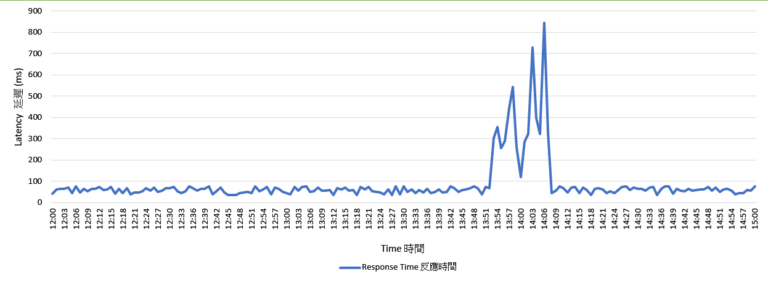
在打合約或工作聲明中。對於伺服器或雲端服務的反應時間 (response time) 和延遲 (latency),以前都會用平均值 (average) 或中間數 (median) 來評量。但是只用平均值或中間數來看,會無法完整的看出整理的延遲反應。 就拿以下的圖表為例,當一個專業的網管,單純的看延遲反應,在下午一點五十一分左右,系統出現了不穩定。延遲衝到了800毫秒。一連持續到約二點零七分左右。直覺可能是其中一個服務器掛掉了。但又自我修復好了。 所幸暴衝不是一直持續,所以可能不以為意。 毫秒 圖一:系統3小時的反應時間 如果是早期的服務水平,這時候會調出平均服務圖表來確認整體的服務是不是有被影響到。一般的服務水平都會訂在 99% 的情況下,服務水平會在 200 或 250 毫秒以下。以平均表來看,在反應最慢的時候也都還在 160 毫秒內。所以看起來也是沒什麼異狀。 圖二:系統3小時的平均反應時間 但是如果是使用 90 百分位數的圖表來看,那可就不同了。90 百分等級是一種描述統計指標。意思是指,在百分之九十位數 (90th percentile) 的正常狀況之下,服務狀況還是可以持續在 200 毫秒內嗎? 圖三:系統3小時的90百分等級時間 圖三指出在十二點三十三分時,百分之九十的正常服務就己經飇高了。一直攀昇到一點五十一分到最高峯約 500 毫秒,之後才開始穩定下來直到約二點零三才恢復過來。那其實不穩定的時間比相象中更久,快要 90 分鐘系統的穩定性一直都是在服務平均水平之外的。 所以結論就是在管理系統時,不能只單看平均服務的數據來確定服務水平是否有達標。利用百分位數的圖表可以更了解系統淺在表現狀況。主統雲端服務都有提供百分位數的監控(如 AWS),請大家多加利用。 參考文獻: 1. https://www.elastic.co/blog/averages-can-dangerous-use-percentile 2. https://azure.microsoft.com/zh-tw/support/legal/sla/cloud-services/v1_5/ 3. https://docs.aws.amazon.com/zh_tw/AmazonCloudWatch/latest/monitoring/cloudwatch_concepts.html#Percentiles